TL;DR: roborock s7 and home assistant work quite well with voice assistant.
So today I wanted to try to find a replacement for home asssitant voice assistant. I successfully setup a voice assistant within home assistant. However, the performance of this voice assistant was not, what I was hoping for. My main scenario was to start my vacuum with home assistant.
Rocki and home assistant
So how do I do that…? Roborock S6 integration with home assistant was easy. However, in order to start room clean with one click, you have to create boolean helper variables for each and a script, that correlates these variables to a room id. Then, based on wich boolean is activated will activate the room clean:
Note here, for the inexperienced home assistant user, you CAN edit everything in code and not in the GUI.
sequence:
- variables:
room_configs:
- name: living_room
boolean: input_boolean.rocki_room_living_room
id: 16
- name: kitchen
boolean: input_boolean.rocki_room_kitchen
id: 17
- name: storeroom
boolean: input_boolean.rocki_room_storeroom
id: 19
- name: dining_room
boolean: input_boolean.rocki_room_dining_room
id: 20
- name: foodstorage
boolean: input_boolean.rocki_room_foodstorage
id: 21
- name: office
boolean: input_boolean.rocki_room_office
id: 23
- name: hallway
boolean: input_boolean.rocki_room_hallway
id: 24
- variables:
selected_rooms: |-
{% set ns = namespace(rooms=[]) %}
{% for room in room_configs %}
{% if is_state(room.boolean, 'on') %}
{% set ns.rooms = ns.rooms + [room.id] %}
{% endif %}
{% endfor %}
{{ ns.rooms }}
- data:
command: app_segment_clean
params:
- segments: |
{{selected_rooms}}
target:
entity_id: vacuum.rocki
action: vacuum.send_command
alias: Selective Cleaning
description: ""
So, how does it work? I activate each boolean on my dashboard and then tell it to clean:
I was really happy here 🙂 And after a few trials, I can safely say, my flat has never been vacuumed so thoroughly!
Kudos to: https://www.youtube.com/watch?v=xe7xjnGqYiU
Voice Assistant
I’m a happy owner of the Voice Preview Edition (https://www.home-assistant.io/voice-pe/) Starting with the voice assistant was not THAT successful. I run home assistant in docker, that might make it a little more complicated.
The integrated home assistant voice assistant (did nothing, and I ended up deleting it)
I also tried the home assistant cloud, and I would have been happy on supporting them monthly, if it gave me a working voice assistant.
Next I tried Local-LLM via hacs. This seemed promising, but neither the llama.cpp on my server, nor an ollama instance on my PC worked properly.
What did work, was integrate it with google-gemini. I just used all google services.
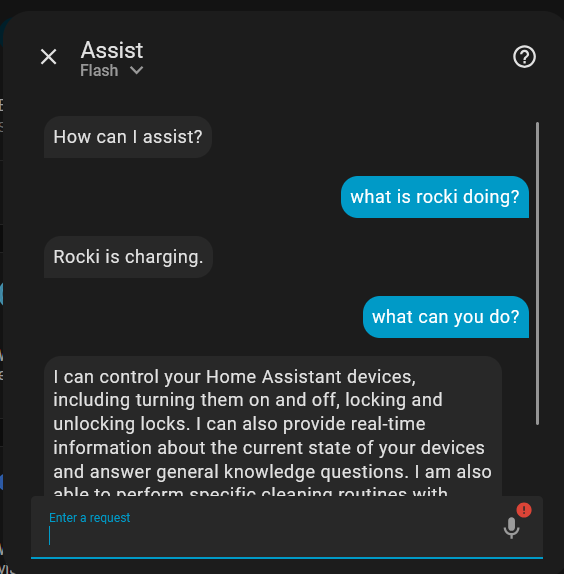
And it worked:
BUT: In order now to start my cleaning i have to issue a voice command like this:
Ok nabu! Activate the hallway, storeroom, kitchen and dining room, then start cleaning
This command mimics how I would do it manually via the dashboard, activate booleans and then initiate cleaning.
Another problem: my nabu device doesn’t engage in a more nuanced dialogue, I cannot chain or anything. Like:
Ok nabu! What time is ti?
>>> It is …
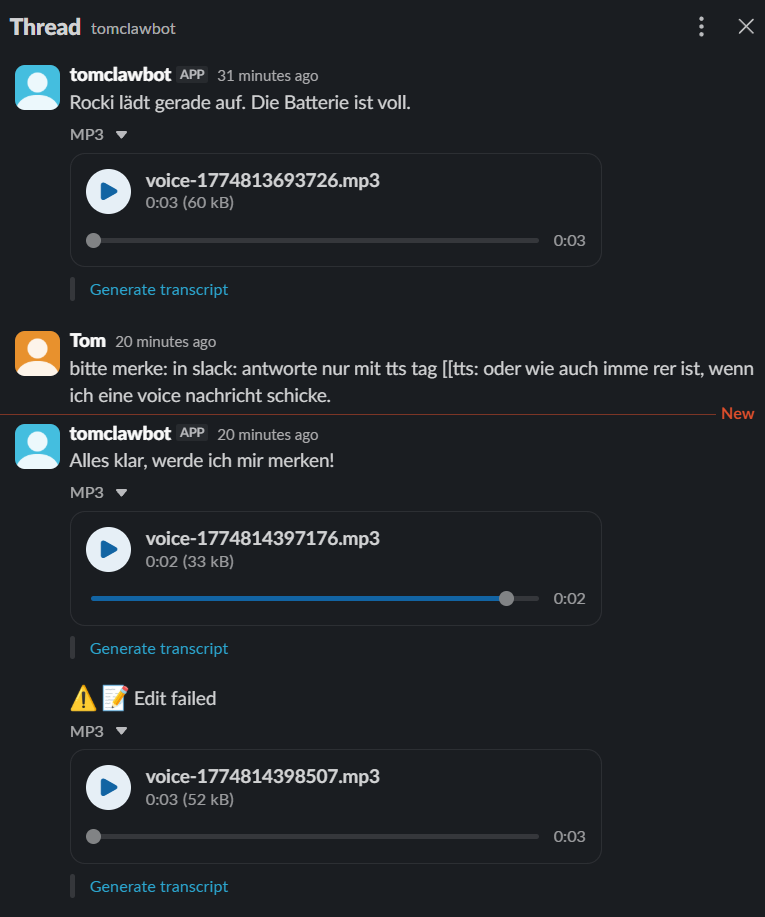
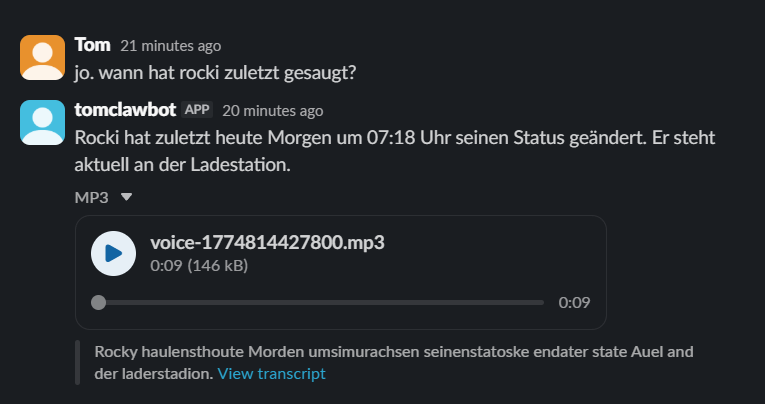
When was the last cleaning?
>>> Last cleaning was …
Ok, so please clean kitchen and dining room again
>>> Starting cleaning…, do you want me to create an automation that rocki cleans the kitchen every Wednesday
No thanks.
OK, so the last part may be over the top, but still, that’s my goal.
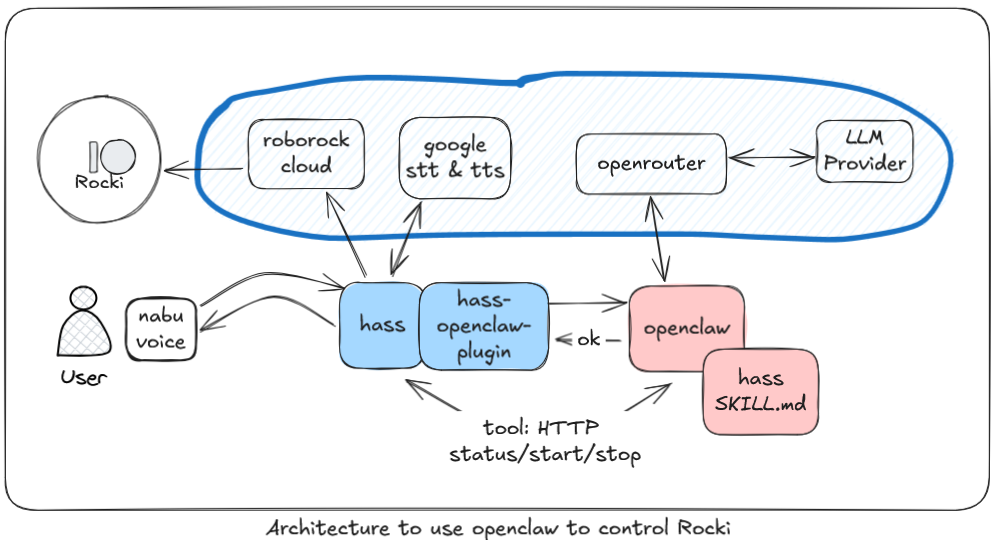
So what was the hacker reaction to this, I figured, I might need to program everything from scratch and do it myself! 😅
Let’s see!